Since I joined Loggi, we have been exploring some techniques for a more data-driven decision making process. In this document I describe some of those, from the perspective of what they bring to the table and their limitations.
The Hierarchy of Evidence is a well established classification of knowledge gathering mechanisms which bring different levels of assertiveness to the decision making process. As you go up in the pyramid, the cost of generating data increases, as does the confidence in the information. As you go down, the easier it is to generate input for your discussion, but the less likely the input will be a true predictor of the effects of a change.
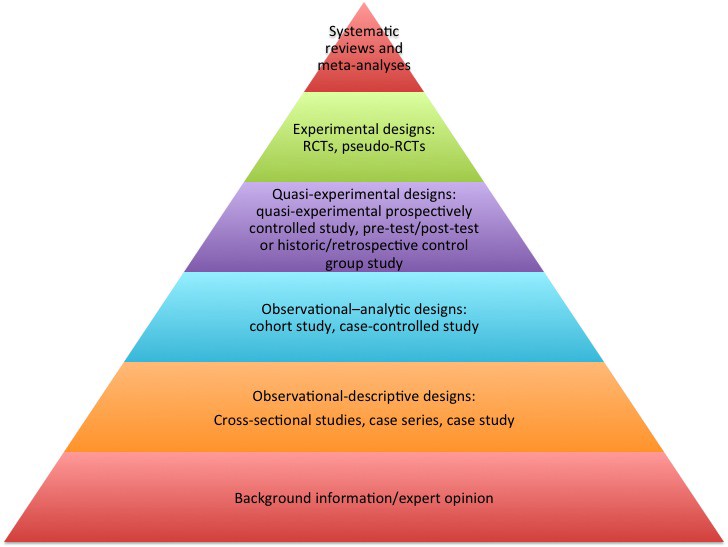
Only a few decades ago companies were operating mostly on the base levels of this pyramid, and discussions around quality of evidence were restricted to the areas of medical clinical trials and social sciences. These areas had limited ability to observe and control its subjects of study, and only the most expensive studies were capable of reaching the higher layers of the pyramid.
As the first big internet companies started to get traction, this all changed. As The Atlantic puts it: “Science has been dominated by the experimental approach for nearly 400 years. Running controlled experiments is the gold standard for sorting out cause and effect. But experimentation has been difficult for businesses throughout history because of cost, speed and convenience. It is only recently that businesses have learned to run real-time experiments on their customers. The key enabler was the Web — Consider two “born-digital” companies, Amazon and Google. A central part of Amazon’s research strategy is a program of “A-B” experiments where it develops two versions of its website and offers them to matched samples of customers. Using this method, Amazon might test a new recommendation engine for books, a new service feature, a different check-out process, or simply a different layout or design. Amazon sometimes gets sufficient data within just a few hours to see a statistically significant difference.”
In 2012, Wired claimed that A/B testing was changing the rules of business. Some parts of Loggi look “big data” enough now, and we want to jump on that bandwagon. On the rest of this document we discuss the shortcomings of our current strategy, based on quasi-experiments , and the techniques we can use to start to run randomised controlled trials (RCT) experiments at minimal extra cost, and benefit from the same unfair advantages other big data companies have been leveraging.
Detailed Design
In this section we discuss the classes of quasi-experiments currently being used in Loggi, their strengths and limitations, and we discuss the caveats and advantages of running RCT A/B experiments using our driver fleet, where we have a meaningful amount of events to enable this technique.
Quasi-experiments and other studies
There is a myriad of possible designs for non-rct experiments. A very simple one in our field is to launch and see what happens to the metric you care after launching. This can be seen as an uncontrolled longitudinal study, or a case series. These experiments have very low internal validity because there is no isolation of external factors. For example, rain can affect Loggi metrics, and if you launch in a sunny week you will be happy with your results even if they are potentially negative. See the graph below from a similar discussion of the shortcomings of this class of experiments done by Airbnb:
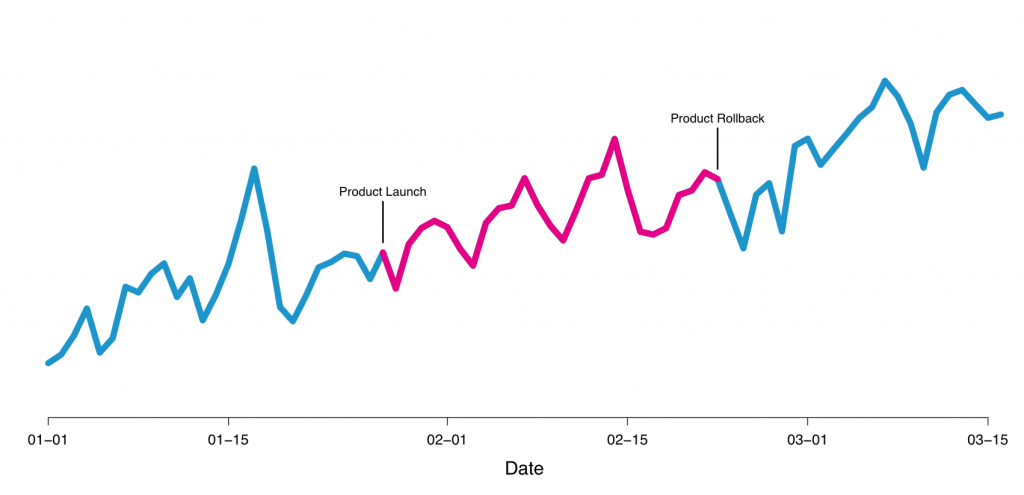
By simply looking at that curve you can mistakenly assume this was a good launch, since the metric goes up afterwards. However, external changes often have more impact than a product change, and through a proper A/B experiment Airbnb found this was neutral and rolled it back. Interestingly enough, later they rolled back the roll back because even though the experiment was not positive, they thought it would be worth the cost to accommodate the use case, a pure product decision, not backed by data, but made safe by data.
These external factors are called confounding factors in experiments lingo, and are very hard to isolate without a randomized controlled trial. Probably the biggest challenge is that they are often hidden variables, in the sense that you don’t even know they exist. More often than not, when something is not going well, we trigger multiple efforts to fix it. In ops, sales and engineering. How do we know that the change we did in eng is really positive, or if it is a loss masked by a much better idea done by ops? Or maybe it just happened that another company in the ecosystem decided to run an experiment themselves, something we can’t even confirm?
One should always favor A/B experiments since they give you strong causality guarantees. Quasi-experiments are much more fragile, even though at a first glance they seem simpler. But sometimes A/B experiments are just not possible, as is the case when you don’t control the assignment of users, or when pure random assignment does not result in well isolated groups. Netflix has recently started to discuss how they still use quasi-experiments for a directional read on causality, for say, the effectiveness of their TV ads (on third party networks). In a recent talk, one can see the level of complexity and care they take to compare users from different geographical cities. For example, they avoid comparing pre-test and post-test averages, and instead uses the full time series of each city to derive predictions, and check how much test and control derive from the prediction. Check some online decks for examples and explanations of quasi-experiments in the human sciences field.
Among the most popular of the quasi-experimental designs are (prospective) cohort studies. These studies are sometimes called follow-up or longitudinal studies. The term cohort comes from the old Roman armies, where it was used to describe a large circumscribed group of similar or identical soldiers (eg, all foot soldiers, cavalry, or archers). They then moved together, as a group, through space and time. A variation of those are retrospective cohort experiments, which are observational studies and sit right below in the evidence hierarchy picture we used. Cohort experiments in general are a cheap and intuitive form of comparing two populations, but have poor validity and are therefore a poor choice for comparing features and their effects. One way to see is that cohort studies can tell you who is different, but you need a/b to find out the what makes them different.
Randomized Controlled Trial Experiments
In the age of big data, randomized controlled trial experiments are often simply called A/B experiments. The definition, nonetheless, is still rather formal and strict, and much care has to be taken in order to produce a reasonable causality proof. Several companies, like Optimizely, VWO and Google offer products which take care of the several details that are needed to get A/B experiments right, while others as Netflix, Twitter or Patreon just give us a glimpse of their frameworks.
Although we are currently discussing adopting some of these tools, many important decisions related to A/B experiments are not abstracted away by them, and we need to discuss them, both now using our ad-hoc infrastructure, and later as we offload the heavy lift. Google has a dedicated Udacity course on the topic, with a great short textual summary, and for the more math inclined, you can dive into the equations on this tutorial.
However, the most important skill is certainly learning how to frame your questions and problems as A/B experiments. For example, it is hard to use an A/B experiment to figure out if restaurants owners prefer more seasoned drivers or are fine with those who just joined. After all, there are not enough sales happening for us to meet A/B experiment criteria, and we cannot isolate that criteria when a sale is closed (or not). But we can use an A/B experiment to see the delivery success rate for a set of restaurants where we randomly assign seasoned or not drivers at each delivery. They are not the same questions, but the response for the latter may be enough for the decision we need to make.
It is a trade-off on which questions you can ask and the quality of the answers you get. You can still use a retrospective study to claim that restaurant owners prefer seasoned drivers, but you will never know what is responsible for the numbers you observed. Maybe you just got a star salesperson dedicated to sell proposals with seasoned drivers only.
Some rules of thumb
Let us assume we want to frame as many questions as we want as A/B experiments. Some of the details we need to pay attention to are how to do the diversion of the users, also known as sampling, how to decide the size of the population, and how long to run the experiment. The response for each of these is quite involving and we discuss them below, but here are Davi’s rules of thumb that can be applied: sample the users randomly without any zooming (e.g., do not filter by hour or city), have at least hundreds of events (converted users) in the experiment every day, and run the experiment for one or two business cycles (e.g., weeks).
Let us visit the first important decision, how to divert your users. This is about saying who goes in an experiment, in its control or neither. Remember, you must have a randomized control, otherwise you are in the quasi-experiment level. This can be implemented by taking a mod of a hashed id. Details matter, so ask for help (a/a experiments and statistical tests can help), and in a full framework, one can use salted hash functions to create many experiment layers. But despite the technicalities, there is still a rather important decision to take: what is the id? For example, we recently ran an experiment using the itinerary Id as the identifier, but it turns out that this gets recreated on retries, and our routes were bouncing around experiment buckets. We fixed that by using the order id instead. The response is not always clear, but the guidance is: always go with the most stable id. Web based experiments sometimes use things like ip address+user agent as a pseudo id, but cookies are more stable and always superior.
The second important decision is the size of the population. To define that, one needs the notion of a conversion (or event) and a baseline conversion rate. For example, your population are offers, and your conversion is the acceptance of an order. Finally, you need to decide what is the minimum effect that interests you. If you want to see if your change increases acceptance rate by 1%, you need way more users than if it suffices to know whether the change is bigger than 10%. With those numbers, you can use Optimizely Sample Size Calculator or other similar sites to get your population size. Besides the nice FAQ and video on that page, you can check many other in-depth explanations of the math.

The third question we need to pose ourselves is how long to run an experiment. The naive answer is to wait for convergence and stop, but the way p-value works, if you mistakenly keep checking for convergence, you will find it even when it is not there. So, you need to be mindful to not call your experiment before you planned. Also, you need to run it long enough so that all important internal variations are represented (e.g., our peak traffic on Mondays). Plan for one or two business cycles.
It takes sometime to learn how to analyze experiments results, but for now, take some time to familiarize yourself with the many caveats in A/B experimentation. There are a lot of tricks, so do not be afraid to ask for help. Check some hints on how to validate a/b tests, some of the must known key issues, mistakes that can invalidate your results, common validity threats and some additional guidelines. A few highlights follow.
The first one is the problem of side effects leaking across the experiment buckets. This is something every experiment in a network-like environment needs to face, and in Loggi this can easily happen as the driver fleet individuals communicate a lot among themselves. There is no easy way around, and often we think about per-city experiments for that, but that breaks the randomized sampling and we no longer have proper RCT due to selection bias, the archenemy of A/B experiments. See how okcupid dealt with this problem, which is probably what Uber and other large systems with similar problems do. Unfortunately, we are not big enough to get there yet, so for now we just try to formulate our hypothesis to not fall into that trap.
Experiments as a Software Engineering Practice
Although the most recognizable format for an A/B experiment is checking the impact of a feature launch, there are some standard formulations with slightly less intuitive definitions that are still very useful as software engineering practices. Two of them are worth highlighting as we use them often at Loggi.
The first one are canary launches. The name comes from the practice used in coal mines to detect hazardous gases by bringing a caged canary down the tunnels. If the bird became silent or died, this was a sign that something was seriously amiss and that the miners should leave. One can see canary launches as A/B experiments where the monitored metrics are the system stability numbers usually tracked by SREs. User assignments follow the usual RCT practice, making this a powerful technique for defining causation, albeit hard to narrow to a specific feature, since the change is the full set of new code in the canary. Usually statistical significance is not closely monitored either because the baseline for failures is so small that any digression is deemed problematic. All of our apps use canary launches nowadays, and our backends also rely on a limited form of it, doing per-machine diversion.
The second one are dark launches. This is like an A/B experiment where you clone your requests for sampling, and you drop your responses to stay restricted to infrastructure side-effects. On dark launches sometimes small variations, like in hardware utilization or in algorithm output, matters, and statistical significance can play an important role. In Loggi, we usually dark launch Vehicle Routing Problems like algorithms to be confident they behave well before applying to the real world.
Final Remarks
Collecting and analysing data by itself is not enough for a successful data driven culture. As seen in the many links shown here, these techniques all have very real limitations and pitfalls. Given the wrong incentives, they can be used to make any point, right or wrong, intentionally or not (see Twitter’s recommendation on HARKing or this video on irreproducible research and its science validity). Being faithful to hypothesis you are studying, and keeping a high level of skepticism is a must. The scientific community as a whole has noticed that risk already, so do not forget your intuition and that of your colleagues are as important as any of these tools.