Why Bother
Writing software is a very expensive process, and most systems we interact with today, as technologists or even as regular consumers, are the product of thousands of years of work by different individuals all across the world.
For example, the Linux kernel alone is estimated to have cost USD 1.4B dollars. Developing a full Linux distro is said to cost 60,000 Person-Years or 10.8B dollars. This is more money than the combined venture funding received by Latin America tech companies ever. But regardless of the fact that none of these companies could afford building a full-fledged distro, all of them benefit from many different flavors of GNU/Linux.
Software might be the first kind of knowledge that can be composed. It is hard to develop, but it is often easy to use, and is not even that hard to combine. And the latter is what brings the real magic. It is the closest thing to “building on the shoulders of giants” in the realm of really building stuff. Thanks to the legal, cultural and intellectual foundation laid out by the Free Software movement and others, this often comes for free. Even when there is a dollar price, from the cloud providers or other commercial mechanisms, it is rarely comparable to the high cost of working out all the details alone.
In this document we try to give some guidance on how to benefit from this collective investment that humanity has done for us, and how to see the evidence of when you should be contributing to the pool, not taking from it. Both are beasts hard to tame, and even harder to master. Nonetheless, here is some wisdom to help.
Applicability

The first question is when you should consider adopting an existing library to solve a problem. The answer is quite straightforward: always. You may not necessarily end up using a library, but the potential benefits are so great that you should at least always spend a bit of time to see what are the choices you have.
Besides the reasons for the development cost described in the last section, there are many other positive aspects in using a well-chosen library. First, future development is paid for. Not only you get the benefits from the code that already exists, but you also get for free future development. For example, from the adoption of or-tools in our codebase to today (roughly 6 months), we have gained almost 2x performance improvements just by bumping versions.
Sometimes libraries can look overwhelming. They have APIs that seem to do more than you need. And you get the feeling that you would be better off by writing the small subset of functionality you need yourself than spending the time putting yourself inside the head of the library author and asking why things are not just what you expect. Be careful on that line, the reality is that you are very likely to bump in the same obstacles that made the library author choose a different path than yours. So, what at first is causing you discomfort, is quite often you are getting the benefits of time-travelling magical hindsight from someone who went through the same journey you are about to onboard.
The trade-offs
Now that you are convinced that you should consider using a library in your codebase, you need to decide which one to pick, if any. Different organizations adopt different strategies, and using some proxy for popularity seems to be the most common, as you can see in this beginner’s guide for choosing a library, this writeup on open source sustainability or this short piece presenting more popularity signals, such as stack overflows questions. Scientific literature on some of these signals, like github stars, show there is good information there.

Although it is better than nothing, I find it an insufficient framework, and in Loggi we have adopted instead a set of orthogonal metrics, based on a model for how libraries interact with our codebase and engineers. The main insight is that third party libraries bring (great) incremental benefits but their costs are compositional. Here is a nice equation to describe it.
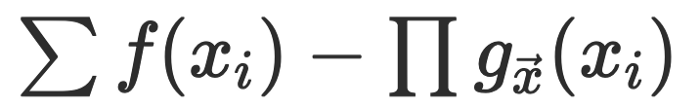
What we are capturing this is that for each library xi we adopt, our productivity is incrementally increased by some amount f(xi), which depends essentially on the library itself. However, we pay an overall penalty by having to integrate the library with our codebase, and that penalty, g, depends on the interaction of the library with all the others in the codebase, x. The overall effect is significant and exacerbated for each library we add, like composite interest, so while we see the summation of benefits, our productivity loss gets multiplied by the more distinct libraries we use.
Let us use a simple example to understand. Assume you have a frontend codebase using vanilla js (i.e., no libraries or frameworks). You decide, very correctly according to our model, to save a lot of work by adopting AngularJS. This is one of the most popular and well maintained frameworks, so it hits home on any “choosing a library guide”. That makes the first component of our equation increase, and has little impact on the second, since you use no other libraries. Now, rinse and repeat, and add another great library to your codebase, ReactJS. Equally popular and well maintained. Now you have a more productivity codebase right? Well, not. The left side of the equation continued to increase, but the right side increased faster, since it is super hard to combine ReactJS and AngularJS and now you have the worst nightmare of many developers.
This is not just a hypothetical example. It happens everyday in many companies, and when it is noted, it is too late. For large organizations, it is often deemed unavoidable, and the microservices movement (and its less popular cousin, microfrontends) focus instead on dealing with that problem at the infrastructure level instead of preventing it. In the past we had in our codebase cocoa, reactjs, react-native, kotlin, angular and other frameworks I don’t even remember, and for every new component in our design system we had to reimplement it in all these codebases. You can’t avoid the dragons, but you need to work hard to keep them at bay.
Before we go deeper in how to estimate f and g in the equation, notice I chose to only model whether we use or not a library, not how much we use it. This yields an important corollary: you can always use a library someone else is using, no questions asked. Without that, the decision making process becomes just too convoluted, and people will fall to analysis paralysis. In practice, it is a reasonable approximation, and reverting past decisions are separate projects, not part of the day to day work.
Computing your choices
To estimate how much benefit and cost a given library can bring to our codebase, we will look at four independent dimensions: value, momentum, surface and dispersion. The first one is where the conversation started: how many engineer-years would take to develop that code in-house. The second is closely related with popularity, and captures how likely your decision is to withhold the test of time. The last two are related to the penalty side of our equation. Surface is about the cognitive cost that a library brings to your organization, and dispersion captures how many roles the library may end (intently or not) playing in your code. Let us try to create a visualization for some definition of these metrics to see how it feels.
Let us talk about value first, which is the simplest concept. We can decide the scale for that is indeed the number of the engineers-years invested in that library. The COCOMO methodology is an established technique for deriving that, and we can find the resulting number for open source libraries in openhub.net. For example, React took 72 years to develop. We will use bubble graph, and encode the time to develop as the bubble size.
For momentum, we want something like github stars, but without the downsides. In particular, some notion of vitality of the project is important to give us confidence that the library will not rot, and hopefully will thrive bringing new value. This being the most common way people pick libraries, others have thought about this problem before, and we will just take a ride on libraries.io SourceRank. That metric goes from 0 to 30'ish, and we will represent it as the color of our datapoint, going from red to yellow to green. Google spreadsheet plots are not that flexible, so we will discretize it to 5 colors. React is very healthy at 34 points, so it gets a nice green tint.
The concept of surface is less commonly talked about, and we couldn’t find any well established metrics for it. This JSConf talk on Minimal API Surface Area is very much on target, and even mentions lodash, my favorite example of a library we should not adopt. It saves a little bit of typing for sure (low value), but it is even funny how it automatically gets mentioned on virtually every code review. The way this article extends the notion of surface cost to the personal life of an open source programmer also connects to the concept we are defining here. Essentially, how many new contact points an extra library brings to your codebase and organization? The larger the surface, more it hurts your codebase, so it better brings a lot of value. We will try to capture that by defining the x-axis of our graphic as the log of the number of files in our codebase with imports from that library. We compute it with some bash-fu: rg “import.*’react” .|cut -d: -f1 | sort -u|wc -l. For react, this yields 3060, whereas lodash scores at 450, and we take the log. Let us see how they look in our graph.
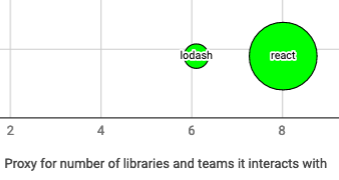
To wrap up our graph, we will use dispersion as the scale for y-axis. This is a way to express how much your library resembles a swiss-knife, the ultimate tool, which can do everything, and does everything poorly. When you pick a well-focused library, it is clear which role it will play in your codebase, and it leaves room for libraries focused on different topics. But if you pick a large framework, which does a lot of things, there won’t be room for another one of those. For example, when we chose Micronaut as the JVM framework for our codebase, we knew we were giving up on Spring (a swiss knife itself). Although this is hard to define formally, we try to proxy it through the number of names a programmer needs to summon to use the library. Again, with some bash-fu we count unique symbols imported in our codebase: rg “import.*’react” .|cut -d: -f2-|tr ‘ ‘ ‘\n’| tr -d ‘{},’ | grep -v ‘from\|import\|\’.*\’;\|^’|sort -u|wc -l. Material-ui is at 164, close to react, and in the other extreme we have quagga2, exporting a single symbol. Let us see the full graph with some of the libraries in our codebase, again taking the log for the axis.
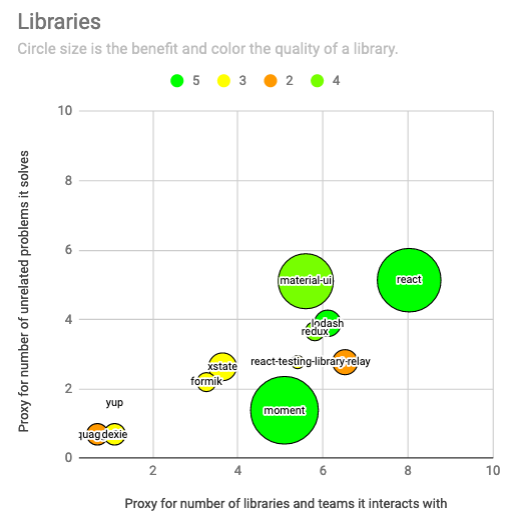
So, value and momentum contribute to the positive side of our equation, f, while surface and dispersion contribute to the negative side, g. Looking at the graph, you want to have most of your libraries close to the plane origin, and you want to be very careful with the right-upper side of the graph, where only a few large, green circles can live. This visualization hints that lodash, redux and relay are not generating the same kind of benefit as the other libraries around them, namely react, material-ui and moment. The fairly new xstate and formik are a bit risky, and react-testing-library is getting a free pass for being a testing-only dependency. Yup, dexie and guagga2 are very specialized and well contained, and hence an easy choice to have in the codebase.
As for the equation itself, it provides intuition, but we don’t actually compute its value for the whole codebase, after all the inputs are noisy and it is an oversimplification of a complex social process. Nonetheless, you want to feel that you can get a positive result. Here is how a localized exercise looks like:
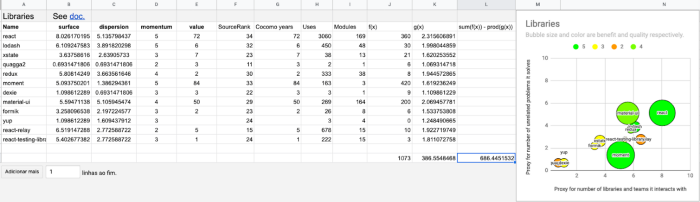
The plot and the whole computation are connected to a google spreadsheet where you just need to feed SourceRank, person-years of development and the output of the bash incantations mentioned here to give your own codebase a try. The final numbers may be too noisy, but I suspect you will learn a lot and be able to think better on your policy of adopting 3rd party libraries.
This text was initially published in my medium.